Every work should have backup for future reference,
This Document contains,Step by step procedure of taking BODS Backup's.
Every work should have backup for future reference,
This Document contains,Step by step procedure of taking BODS Backup's.
Introduction
This document provides information on the types of BODS Repositories (Local, Central and Profiler) that should be set up and the number of repositories of each type that can be set up in various environments (Dev, Int, UAT and Prod).The actual number of repositories will depend on project specific requirements.
This document can be used as reference to work out the actual number of repositories required. This document does not explain how to create various repositories, how to use central repository, configure groups and users, assign access to users for repositories etc as these are already detailed in BODS Technical Manuals.
Considerations and Assumptions
Development (Dev)
Integration/Pre-UAT (Int)
Quality Assurance/User Acceptance Testing (UAT)
Live/Production (Prod)
BODS Repositories
Below table provides information on the number of repositories of each type required
| Dev | Int | UAT | Prod | Comments |
LR | N+1 | 1 | 1 | 1 | N LR’s in Dev env for N developers and 1 additional LR as MR. Minimum 1 LR in each environment is mandatory for Jobs to run. |
CR | 1 |
|
|
| CR is optional however it is highly recommended that a CR is used even in single developer projects. |
PR | 1 | 1 | 1 | 1 | PR is completely optional and only required when basic data profiling is not sufficient. |
N: Number of Developers.
LR: Local Repository.
CR: Central Repository (Only Secure Central repository is considered).
PR: Profiler Repository.
MR: A Local Repository specifically for Code Migration (Code promotion) purpose in Dev environment however no code changes are carried out in this, Only Development Lead/Code Consolidator is allowed to access this repository.
Explanation
N Local Repositories in Dev environment and 1 Local Repository in each higher environment would meet the minimum number of repositories required for base level of functioning then what is the need for Central Repository and an additional local repository just for migration purpose in dev environment?
Need for Central Repository
Central Repository supports multi user development as it enables parallel development and hence reduces development timelines, for example developers can work on different DataFlows which can later be integrated into a Job. Even though Central Repository is generally used in multi developer scenarios it is found that using central Repository in single developer scenarios can also be very useful as it also provides version control and code comparison options (especially comparisons with dependents option) within BODS tool and these features can save lot of time and effort during development/enhancements.
Need for an additional Local Repository as Migration Repository in Dev environment
There are two key reasons for including a migration repository
The way to use migration repository is explained below
Ensure migration repository is in sync (same code as in Prod). Once all the developers check in their code into central repository a Development lead/Code consolidator can get the consolidated code from central repository into migration repository and run the Jobs and check if the integrated BODS code works fine as expected and then this repository can be used to export the code into a .atl file for code promotion. Without this repository, the Developers would work on their local repositories and then one of the developer’s local repositories would have to be used for code consolidation and code migration to Int environment. This approach will have multiple risks and limitations. The developer whose repository is being used for consolidation will not be able to work on other changes.High chances of unintentional code changes progressing to Int environment. Also there is a risk of code corruption and hence corrupted code progressing to Int environment when developer’s local repository gets corrupted.
Hope this document helps those who are new to BODS and are setting up BODS repositories. Also, I am interested to know from other BODS Professionals about repository set up in your respective projects.
Thanks
Hi All, I would like to share some basic answers of some critical questions commonly faced during SAP BO Data Services learning.
What is the use of BusinessObjects Data Services?
Answer: BusinessObjects Data Services provides a graphical interface that allows you to easily create jobs that extract data fromheterogeneous sources, transform that data to meet the business requirements of your organization, and load the data into a single location.
Define Data Services components.
Answer:Data Services includes the following standard components:
What are the steps included in Data integration process?
To know the answer of this question and similar high frequency Data Services questions, please continue to,
What are the steps included in Data integration process?
Define the terms Job, Workflow, and Dataflow
Arrange these objects in order by their hierarchy: Dataflow, Job, Project, and Workflow.
Project, Job, Workflow, Dataflow.
What are reusable objects in DataServices?
Job, Workflow, Dataflow.
What is a transform?
A transform enables you to control how datasets change in a dataflow.
What is a Script?
A script is a single-use object that is used to call functions and assign values in a workflow.
What is a real time Job?
Real-time jobs "extract" data from the body of the real time message received and from any secondary sources used in the job.
What is an Embedded Dataflow?
An Embedded Dataflow is a dataflow that is called from inside another dataflow.
What is the difference between a data store and a database?
A datastore is a connection to a database.
How many types of datastores are present in Data services?
What is the use of Compace repository?
Remove redundant and obsolete objects from the repository tables.
What are Memory Datastores?
Data Services also allows you to create a database datastore using Memory as the Database type. Memory Datastores are designed to enhance processing performance of data flows executing in real-time jobs.
What are file formats?
A file format is a set of properties describing the structure of a flat file (ASCII). File formats describe the metadata structure. File format objects can describe files in:
Which is NOT a datastore type?
File Format
What is repository? List the types of repositories.
The DataServices repository is a set of tables that holds user-created and predefined system objects, source and target metadata, and transformation rules. There are 3 types of repositories.
What is the difference between a Repository and a Datastore?
A Repository is a set of tables that hold system objects, source and target metadata, and transformation rules. A Datastore is an actual connection to a database that holds data.
What is the difference between a Parameter and a Variable?
A Parameter is an expression that passes a piece of information to a work flow, data flow or custom function when it is called in a job. A Variable is a symbolic placeholder for values.
When would you use a global variable instead of a local variable?
Please watch for this space for more questions with answers.
Thanks
Venky
SAP BusinessObjects Data Quality Management, version for SAP solutions (DQM for SAP), enables you to embed support for data quality directly into SAP ERP,CRM and MDG applications. Start by entering a new customer, supplier, or partner record using the SAP ERP, SAP CRM , SAP MDG applications. Then this version of SAP BusinessObjects Data Quality Management software corrects components of the address, validates the address based on referential data sources, and formats the address according to the norms of the applicable country. This solution helps in avoiding the duplicate entities entering into your SAP ERP, CRM and MDG applications(supports different MDG data models for address validation and duplicate checks) and also helps in searching and improving your existing data.
The following tutorials have been developed to help you find answers to the most common questions about using SAP BusinessObjects Data Quality Management 4.0, version for SAP. Please refer to the User guide at Data Quality Management for SAP Solutions – SAP Help Portal Page for the complete and detailed steps.
If you are NOT using BAS-DES dupe check and considering a more generic duplicate check
for all data models, as an alternative, you can set up the following.
CONFIGURING THE BREAK KEY
Goal of this document
This document provides you with a procedure to assist you organizing and performing the data transfer from the legacy system.
It describes a methodology for data migration I used successfully in different implementations. It is based upon my previous experiences. There is no warranty on its content or on the results. This guide gives you suggestions. It is up to you to take the hints and make up your own methodology.
Common Terminology and Abbreviations in Migration Projects:
Note: The terms SAP and R/3 are both use interchangeably to refer to SAP R/3 system.
Big Five: When referring to the Big Five, it means Material Master, Customer Master, Vendor Master, Bill Of Materials (BOM) and Routings.
Business Objects: To help in the analysis and transfer process, the data are not treated as tables or field contents but rather as objects in term of business operational. These are called Business Objects.
Business Object DC responsible: Responsible of the conversion process (Legacy data source and integrity, mapping, conversion rules, etc.) and for the respect of the planned schedule for his Business Object.
Business Object Owner: The one that owns the information in the everyday business. This is the person that will make the strategic choices on functional requirements for the business object and that will do the final validation of the converted data. Can be identified by finding “The highest hierarchical person who will be directly and mostly affected if the business object does not work”
Data Conversion & Data Migration: The data conversion process. “Data conversion” and “Data Migration” terms are used interchangeably in the document.
DC: Abbreviation for the data conversion process.
Domain: Functional domain within the project, like Finance, Sales, Production, etc.
Flat File: A file format used to import data into SAP. The flat file is a plain text file with a tab separator between fields. It can be easily generated from Excel or Access.
Intermediate file: An Excel, Access or other type of file, which is manually manipulated in a process between the LS extraction and the flat file generation.
LSMW: Legacy System Migration Workbench. It is a SAP tool for conversion that permits data loading using flat files extracted from the Legacy System.
Cross reference table or X-Ref table: A table that shows the relation between fields when one value is related to a parent field. For example, the "Sales Organization" will be set accordingly to the material type.
WBS: Work Breakdown Structure.
Overview:
Implementing SAP is an important challenge, both in terms of resources (people, money, time) and in business process. A lot is at stake and, for most of you, failure is not an option you can afford. To put all odds on your side, you need a good methodology. One that will provide you with a realistic planning, a solid organization, a way to manage the process and control tools to detect and correct slippage before it becomes a problem.
Main steps of the conversion methodology:
Before you even start to work on specs, you must first get organized. Getting a good planning and organization structure take about two weeks for the first draft, which will leave you with some questions on project organization. Getting a complete and final planning will take at least one more week. Any unsolved issues on these will haunt you throughout the project, so finish this completely before stating any other step.
The data conversion requires functional and technical resources from most departments. These same resources will most probably be involved in other part of the project. For this reason, the risk of conflicting task is high and can quickly lead to a bottleneck where key peoples are overloaded. For this reason, you should consider the data conversion as a project within the project. This translates into the preparation of a complete conversion plan that will help you go through the process and will permit to foresee and solve the conflicting resources usage before the bottleneck ever occurs.
The main steps of the data conversion are:
Organization of the data conversion (Project manager & data conversion coordinator)
Going on with the Business Objects data conversion (The resource responsible of the Business Object DC)
A Business object is a general category for data that defines something like material master, vendor master, stocks, orders, purchase requisitions or organizational units. The first step is identifying which business objects (Objects) are required in your SAP implementation.

There are three types of data involved in a SAP system: master data, transactional data, and historical data.
The data transfer method you choose will determine the types of resources you need. For example, you may need temporary employees for the manual data entry and programmers for writing your own extraction programs. You need to know both what data is in your legacy system and which SAP applications correspond to the business objects that will be transferred. One person does not have to know all of this, but the people who know this information should work closely together.
Main Business Objects sequence of conversion:
CONVERTING A BUSINESS OBJECT:

The purging and cleansing of the Legacy System will save you lot of time and effort in the following steps of the conversion. Start this as soon as possible and do as much as possible. This can be done without specific knowledge of SAP.
Before transferring data from your legacy system, delete all the old and obsolete data. For example, you may delete all one-time customers or those for which there were no transaction in the last two years, also delete unused materials.
This process corrects data inconsistencies and ensures the integrity of the existing data during the migration process. For example, there are often lots of inconsistencies in Customer and Vendor address fields. You will quickly find that SAP will not let you load any address fields unless you get them clean.
The documentation of each business object will contain the Data conversion rules (or specification), which include:
From which Legacy system(s) are we extracting the data and how. Document here specific steps that need to be taken.
What are the cleaning steps to be taken and extraction filters to be used.
Guidelines to apply or rules that is used by many fields (thus avoiding to retype it and making updating easier as it is only in one place).
Which SAP fields to use and how do we get the final value for each SAP field.
About the Rules
General rules are the one that does not yield directly to a field value. For example the way in which we differentiate the material types in the Legacy System is such a rule. Field rules are those that give a value for a specific field.
This is a crucial one. When discussing or writing notes, ALWAYS refer to a field in the form TABLE-FIELD. You will quickly realize that as the project go, different people will start using different names for the same field. As well they may start using the same name for different fields.
On top of this, some fields exist in different views in SAP master data. Sometime it is the same field that is shown at two places while other times it is really two different fields. The best way to know which case apply is to have the TABLE + FIELD information.
Example:
In Material Master, the field «Availability check» exists in the "MRP2" and the "Sales Gen" views. If you look at the TABLE-FIELD of each view you get :
MRP2 : MARC-MTVFP
Sales Gen : MARC-MTVFP
In both cases the TABLE-FIELD name is the same, so it is the same field.
In Customer Master, the field " Terms of Payment' exist in "Payment Transactions" and "Billing" views. If you look at the TABLE-FIELD of each view you get :
Payment Transactions : KNVV- ZTERM
Billing Views : KNB1- ZTERM
It is not the same field. In the payment view, the field is linked to the Company Code while for the Billing view it is linked to the Sales Organization (you find this by looking at the tables keys). So both of these fields can have different values

Material Master involves all the domains and may require anywhere from 20 fields to a few hundreds depending on the complexity of your implementation. Some fields will be used by different domains while others will be used by only one domain but its value will have an impact on functionality used by another domain.
This is the most complex Business Object to document and, at the same time, it is the one you must start with in you conversion process.
1st step : Selection of the fields by each domain
In Material Master, some fields can be entered / modified in different views. For example, the field “Goods receipt processing time in days (MARC-WEBAZ)” exists in views Purchasing, MRP2 and Quality management. When doing the rules and the load program, the same field can’t be in different views. To solve this, proceed as follow:
See with all implicated domains who are the lead for the field and decide in which view the field should be included.
Taking the example of the field “Goods receipt processing time in days (MARC-WEBAZ)”, it can be decided among the domains to put it in the Purchasing view (and nowhere else).
Material Master Conversion:
High Level Process Design

These are all the major views involved in Material Master Object:
Usually the Function specification Owners will do the recording method to capture all the fields on the above views and prepare the Mapping Logic.
The most complex design involves in Plant merging and Classification Merging. (Refer High Level Process Document)
CSG Split: Customer Segment Group
A member group of the type customer segment group is a collection of users, as defined by the Seller or merchant, who share a common interest.
For Eg: A mining Company has CSG’s like Cerro Matoso(CMSA),Met Coal (MTCO),Base Metals (BASE) etc.,
Based on CSG’s the data need to be split up before loading through LSMW for valuation.
Other Business Objects Conversion:
For the other BO, because they are simpler than Material Master and involve fewer people, we will start directly with the Conversion rules document. It is in this document that we will both, decide which fields we need and, in a second step, start working on the rules.
Here are some samples of BO conversion rules.
BOM conversion rules sample

Open Account Receivable conversion rules sample

Vendor Master conversion rules sample

Example of general rules
G000 | Note that SAP term “Security deposit” equal “Retention” in PRMS |
G001 | Type of transaction TYPE field in PRMS : Partial PMT: “Pay.” Credit Memo: “Cr M.” Debit Memo: “Dr M.” Invoice : “Inv.” Non A/R cash: “Non AR” Adjustments: “Adj” Any other type is an error. |
G002 | Validation to apply both at extraction and load. Partial PMT………. must be negative in PRMS, if not ERROR Credit Memo………must be negative in PRMS, if not ERROR Debit Memo……….must be positive in PRMS, if not ERROR Invoice……………..must be positive in PRMS, if not ERROR Any other type is an ERROR. |
G003 | LSM Load parameters KTOPL - Chart of account : CA00 BUKRS – Company code: 0070 GSBER - Business Area : 0040 BUDAT – Posting Date : “05-31-02” or last day of last closed period. OFFSET – Account (2) : REPRISECL SKPERR – Skip err : X |
Legacy System Migration Workbench (LSMW):
LSMW is used for migrating data from a legacy system to SAP system, or from one SAP system to another.
Apart from standard batch/direct input and recordings, BAPI and IDocs are available as additional import methods for processing the legacy data.
The LSMW comprises the following main steps:
But, before these steps, you need to perform following steps:
Methods used for data migration like BDC, LSMW and Call Transaction
All the 3 methods are used to migrate data. Selection of these methods depends on the scenario, amount of data need to transfer. LSMW is a ready tool provided by SAP and you have to follow some 17 steps to migrate master data. While in BDCs Session method is the better choice because of some advantages over call transaction. But call transaction is also very useful to do immediate updation of small amount of data. (In call transaction developer has to handle errors).
SO Bottom line is make choice of these methods based of real time requirements.
These methods are chosen completely based on situation you are in. Direct input method is not available for all scenarios else, they are the simplest ones. In batch input method, you need to do recording for the transaction concerned. Similarly, IDoc, and BAPI are there, and use of these need to be decided based on the requirement.
Try to go through the some material on these four methods, and implement them. You will then have a fair idea about when to use which.
Difference between lsmw & bdc
BDC- It is Batch data communication. It’s used for data conversion from legacy system to SAP system. Only technical people can do it. Tcode is SHDB.
LSMW- It is legacy system migration workbench. Its also used for data conversion from legacy system to SAP system. But it is role of functional consultant.
There are 14 steps in LSMW. As soon as you complete the one step, automatically it will go to next step.
In general you can use LSMW. But if you want to transfer more than 40,000 data, then it is not possible in LSMW. That time you can take help of BDC
LSMW data migration for sales order VA01 / XD01 customer.
Read Ina Felsheim's blog to find out about integration use cases related to SAP Data Services, Information Steward and Master Data Governance.
SAP Announces End of Life for SAP Rapid Marts
Important information for our Rapid Mart customers
What is dirty data costing you?
Intrinsically, you know that you need good data. But how far do you need to go? What are the real costs incurred if you DON’T have clean data? Check out this new SAP Data Quality infographic, which highlights the probably extent of your data quality problems, and the costs associated with those problems. This blog by Ina Felsheim also links to the popular Information Governance infographic.
Data Profiling and Data Cleansing – Use Cases and Solutions at SAP
While some organizations have set up enterprise wide data governance projects including managing and tightly integrating People, Processes, Policies & Standards, Metrics and Tools other companies are still in the starting phase of mostly departmental data cleansing activities. Recent research from Gartner still indicate that the poor data quality is a primary reason for about 40% of all business initiatives fail. Read more in this blog by Niels Weigel.
Data Quality Performance Guide
This document from Dan Bills provides performance throughput numbers for data quality capabilities within Data Quality Management and Data Services v4.2.
SAP Data Services Product Tutorials
This document outlines several videos, blogs, tutorials, and other resources to help you learn Data Services.
SAP Data Services 4.2 and SAP Information Steward 4.2 entered Ramp-Up back on May 13th 2013 as General Availability for a planned duration of 6 months. As scheduled both have been released to customer on December 6th 2013.
The final products ready for download are:
Note: SAP took the same approach with SAP BI 4.1 released earlier this year whereas they have entered Ramp-Up with SAP BI 4.1 SP00 and was officially released with SAP BI 4.1 SP01.
The software can be downloaded as a full installation or update:
http://service.sap.com/support> Software Downloads > Installations and Upgrades > A - Z Index > D > SAP Data Services > SAP Data Services 4.2
Microsoft Windows:
Linux:

http://service.sap.com/support> Software Downloads > Installations and Upgrades > A - Z Index > I > SAP Information Steward > SAP Information Steward 4.2
Microsoft Windows:

Linux:

Myself and I'm sure many of you have been waiting for this release for quite some time. I'm sure for one or both of the following reasons:
Customers with implementations such as SAP BI 4.0 or IPS 4.0 and SAP DS 4.1 have been left unable to patch BI to SAP BI 4.1 (SP01 or SP02) when it was released few months ago.
This is of course because of the infamous "compatibility matrix". SAP Note 1740516.
Note: I'll be testing this ASAP on my test environment and contact my customers in January for a series of long and awaited BI and DS (IS) updates!!
See my installation notes:
Here are some helpful documentations:
I'll continue to add content here as I learn more. My main focus is BI Platform so this is always going to be architecture related. I'll let much more knowledge able people than me deal with the new features in those products!
See more blogs and articles here: BI Platform, Enterprise Information Management, Data Services and Data Quality, SAP Information Steward.
As always, I'd be happy to hear your comments, suggestions and experiences with these releases.
Thanks!
The goal of this document is to understand and implement the Global Address cleanse Transforms to Assess the quality of the Address data and to figure out the bad address data
Step 1: Create a New Job and add a Dataflow

Step 2: Inside the Dataflow, Select the source of address data from a table as shown below

Step 3: Select the Data Quality Transforms from the local object library pane and select the Global Address cleanse Transform i.e., UK_Address_Cleanse(Based on your address directory & licensing) as shown below

Step 4: Connect the Source data via Query Transform (if needed) and connect with UK_Address_cleanse Transform and then with the Target Table.

Step 5: Now open the Global Address Cleanse Transform and assign the Inbound attributes in the Input Editor as shown below.

Step 6: Goto the Options Tab and select the Address directory path and change the Generate Reportdata option as ‘YES’

Step 7: Go to Output Tab and select the 4 columns(Status Code, Info_Code, Quality_Code, Assignment Level) as shown below

Step 8: Save & Execute the Job. In the Execution properties, select the Export Data Quality Reports option.

Step 9: once the Job is executed, then log in to the Data Services Admin Console and click the Data Quality Reports

Now you can able to see your Job and corresponding Quality Reports got exported.

If you select the Quality Code Summary Report, this will show the Quality of your address data

Each Quality code implies different meaning
And the below Summary chart shows the same.

You can click on each Quality code and drill down up to the record level for making further analysis and corrections.
Cheers
John
Pre-requisites
Need the grant's
Create session,
Create view
Create sequence to
Create Procedure
There are two ways to create a repository, through the operating system with the following command:
./repoman –Uuser –Ppassword –Stnsnames –Noracle -c -o
Where "repoman" is the application, "-U" option is the user, the "-P" option is the password, the "S" option is the connection string in case the above is the tns, "- N c "type database, the" "is to create, and the" -o "is to force a new creation if there is already a user.
Below is an example of creating, through the operating system.

Or through the Data Services Repository Mananger application installed on the backend.

Command line or scripted deployment for BODS ETL code (atl files) is not straightforward, SAP recommends to use central repository approach for code movement and deployment across various environments. This paper provides a proven method to achieve command-line deployment of atl files to local repositories. This approach is out of our requirement and currently using for our code deployment.
I have developed and tested for BODS4.X in LINUX and UNIX environments , with minor adjustments to these commands we can execute on windows installations. All code snippets are tested for for BODS4.x on LINUX version
“al_engine” is the master piece and facilitates all operations on metadata, like deploying code from command line, altering datastores, generating executable script for jobs. The GUI approach uses this utility to manage repository metadata.
Note: al_engine command usage and options are provided in Appendix section.
All we have developed is basic shell scripts and couple of pearl scripts (when needed a hash comparison), playing with datastores was the hardest part of whole exercise and then creating execution command comes next complex one.
This is back-end deployment process and needs .atl file export of the code need to be deployed to the repository.
We developed separate individual script for each purpose like checking active process in the repository, backing-up the repository, deploying atl file to repository, updating datastores with environment specific configurations, generating the execution command for a specific job, here comes the next challenge that is collaborate all to gather and develop a master script do drive all these individual pieces with greater flexibility and takes care of all possible exceptions. I achieved that by developing one master script with lot of custom options which gives greater flexibility to the user to drive any of the functionality i.e. one script can do all job it just the options need to be supplied by the user. This was the major achievement.
I have organized this document in sections each section talks about individual operation needed for deployment, final section talks about the master script usage; have provided some code snippets in appendix section to help your development.
This section talks about any active jobs currently running in the repository, the deployment may be inconsistent and could lead to corrupt repository if there are any common objects between the active job and the atl file being deployed to the repository. If there are no shared objects it may be safe to go sometimes but it is not recommended to move forward with deployment if there are any actively running jobs.
This script is responsible for notifying any active running jobs in target repository, this script have capability to notify the user by an e-mail notification after the process is completed and there are no active processes in the repository.
Code snippet:
SELECT INST_MACHINE SERVER,
SERVICE DI_PROCESS,
to_char(START_TIME,'MM/DD/YYYY HH24:MI:SS') START_TIME
FROMal_history
WHERE service NOTIN('di_job_al_mach_info','CD_JOB_d0cafae2')
AND end_time ISNULL;
Note: This query need to be executed in the target repository database
This query lists all processes/jobs with end time NULL which means the process still in progress. For all completed jobs end time will be timestamp of completion. We may cannot completely relay alone on this query because sometimes because of abnormal job aborts BODS metadata may store NULL in end time field. In combination to this of we use the operating system’s process pool also then it will give a solid evidence that there is an active process running in background, below is shell cide snippet for that.
UNIX/LINUX code snippet:
PROCESS_COUNT=$(ps -ef | grep al_engine | grep -i $REPOSITORY | grep -i $REPOSITORY_DATABASE | wc -l)
Refer Appendix for parameters in detail
A shell script with these two snippets can be programmed to poll these two commands for 5 minute intervals and notify the user when there are no active processes in the repository; this will save time and provides flexibility to the administrator.
This step is important and essential; we can easily get back the previous state of the repository if something goes wrong with current deployment code. Again al_engine command is used to back up the repository code. There are options to export specific object from the repository too.
BODS 4.x version mandates the passphrase for every atl export from the repository, and same passphrase need to be supplied while importing the atl file to any other repository. While importing If the passphrase is wrong or blank all datastore passwords will be invalid and need to reenter only the passwords of each datastore.
Below code snippet is to export a repository
UNIX/LINUX code snippet:
al_engine -U$REPOSITORY-P$REPOSITORY_PASSWORD -S$DATABASE_INSTANCE-N$DATABASE_TYPE-passphrase$PASS_PHRASE-Q$DATABASE_SERVER -X
Refer Appendix for parameters in detail
This script will generate “export.atl” file in current directory with full backup of the repository, we can rename and move this file to desired location for future purpose usage.
Previous two sections are preliminary steps to make sure if something goes wrong (Backup) or to prevent something going wrong (check active process) .This section talks about the actual deployment process that importing atl file to the repository, this step is a typical step how we import atl file/code to a repository.
Below code snippet is to import atl fileto a repository
UNIX/LINUX code snippet:
al_engine -U$REPOSITORY-P$REPOSITORY_PASSWORD -S$DATABASE_INSTANCE -N$DATABASE_TYPE-passphrase$PASS_PHRASE-Q$DATABASE_SERVER -f$FILE_NAME
Refer Appendix for parameters in detail
This command imports the atl file to the repository, if there are any error/issues with the file or import this command will throw an error, if the import is successful this will display a success message on the console. We can import only one atl file with one command, this command should be executed several times if more than one atl files need to be executed.
$PASSPHRASE should match the passphrase passed to the atl file at the time of export from local repository , for an incorrect or blank passphrase atl file still gets deployed/imported to the repository with blank passwords of all datastores from the atl file.
The datastore configuration may not be the same across Development, QA and Production environments, we can automate or achive through a command to update datastores information of a repository. If the datastore already available with respective configuration in each environment we may can skip that datastore configuration from the atl export. A brand-new datastore need to be configured correctly in the environments. We can achieve this through command-ine.
UNIX/LINUX code snippet:
al_engine -N$DATABASE_TYPE-Q$DATABASE_SERVER -S$DATABASE_INSTANCE-U$REPOSITORY-P$REPOSITORY_PASSWORD -jd$DATASTORE_XML_FILE
Refer Appendix for parameters in detail
One configuration text file for all datastores with details (datastore name, configuration name,database instance, schema and password), will help to set the configurations in one file and use the same file to update datastores, the code snippet need to run iteratively for e6ach datastore configuration
We have tested this process only for ORACE database, other databases and other type of datastore configurations must be tested before implementation.
Datastore configuration information is case sensitive, make sure you are following the same case
Al_engine don’t play a bigger role in creating execution command, instead we will write all values and construct the execution command for a job. We need to read the object ID from metadata tables and all other values are from the environment. Generally the execution command is exported from management console; this will not facilitates the developer to pass dynamic values to the global variables defined in the job. i.e. if we need to pass values for the global variables from external environment , it is not possible to generate a generic executable command form management console.
Be low code snippet facilitates to
UNIX/LINUX code snippet:
${LAUNCHER_DIRECTORY} \"${LOG_DIRECTORY}\" -w \"inet:${HOST_NAME}:${PORT_NUMBER}\" \" -PLocaleUTF8 -R\\\"${REPOSITORY_PASSWORD_FILE_NAME}.txt\\\" -G\"${JOB_GUID}\" -r1000 -T14 -Ck -no_use_cache_stats ${CONFIGURATION_NAME}-LocaleGV ${GLOBAL_VARIABLES}-CtBatch -Cm${HOST_NAME}-CaAdministrator -Cj${HOST_NAME}-Cp{PORT_NUMBER} \"
UNIX/LINUX code snippet with Global Variables dynamic values for them:
${LAUNCHER_DIRECTORY} \"${LOG_DIRECTORY}\" -w \"inet:${HOST_NAME}:${PORT_NUMBER}\" \" -PLocaleUTF8 -R\\\"${REPOSITORY_PASSWORD_FILE_NAME}.txt\\\" -G\"${JOB_GUID}\" -r1000 -T14 -Ck -no_use_cache_stats ${CONFIGURATION_NAME}–LocaleGV-GV\"\$gv_parameter_1 =`AL_Encrypt "'$1'"`;\$gv_parameter_2=`AL_Encrypt "'$2'"`;\" -CtBatch - Cm${HOST_NAME}-CaAdministrator -Cj${HOST_NAME}-Cp{PORT_NUMBER} \"
Parameter | Description |
$REPOSITORY | Local Repository name, typically the database schema name used for the repository |
$REPOSITORY_PASSWORD | Password for above schema |
$DATABASE_INSTANCE | Database instance name on which this repository (schema) available |
$PASSPHRASE | Mandatory for BODS 4.X, optional for BODS 3.X versions
Alpha numeric string serves as password for this for atl file.
If not provided same passphrase at the time of import of this atl file all datastores will have blank passwords. |
$DATABASE_SERVER | Physical machine name of the server on which the $DATABASE_INSTANCE is installed/available |
$DATABASE_TYPE | Type of the database Eg: Oracle |
$FILE_NAME | .atl Filename to import to the repository This can be a full qualified absolute path with filename (including extension) |
$DATASTORE_XML_FILE | XML file absolute path, with datastore credentials, see below for sample xml file. |
Creating shell/Executable script | |
$LAUNCHER_DIRECTORY | Absolute path of the BODS launcher Typically at /local/apps/bods3/dataservices/bin/AL_RWJobLauncher |
$LOG_DIRECTORY | Absolute path for to produce log files Typically at /local/apps/bods3/dataservices/log |
$HOST_NAME | BODS server machine/host name |
$PORT_NUMBER | BODS executable port number (configured at the time of installation) |
$REPOSITORY_PASSWORD_FILE_NAME | Password file name. If password file is at different location than the default provide absolute path Default password file path: /local/apps/bods3/dataservices/conf |
$JOB_GUID | Job ID from metadata tables below is query to get the job ID from metadata tables
selectdistincttrim(GUID)from AL_LANG whereupper(name)=upper('<JOB_NAME>')
Above query should be executed in target repository database schema. |
$CONFIGURATION_NAME | System configuration name if there are multiple configurations in the BODS environment. Blank for default or no system configurations. |
Below is the sample XML file with datastore configuration, first 32 0’s are specific to BODS 4.X version, for previous versions 3.X versions the first 32 0’s can be skipped.
There should be one xml file per configuration per datastore, for example if you have 10 datastores with two configurations each you need to generate 20 XML files.
Automate with a shell/pearl script which reads datastore configuration file, generate below XML file per confutation and update the respective datastore dynamically within the script and remove this XML file immediately after the update is done.
Initially for BODS 3.X version plain XML file was used (without 32 0’s in the beginning of the file), for BODS 4.x the tool expects every value, file passed in encrypted format, the 32 0’s string says this file is encrypted,(Actually not) this is a work around.
SampleXML file
00000000000000000000000000000000<?xmlversion="1.0"encoding="UTF-8"?>
<Datastorename="MY_DATA_STORE">
<DSConfigurations>
<DSConfigurationdefault="true"name="Configuration1">
<oracle_host_string>ORACLEDATABASESID</oracle_host_string>
<user>SCHEMA</user>
<password>PASSWORD</password>
</DSConfiguration>
</DSConfigurations>
</Datastore>
-A : BW Request ID consisting of RequestID [30 characters], Selection Date [8 characters], Selection Time [6 characters]
-v : Print version number
-D : Print debug messages
-DRowCount=<n>
-DASID=<s>
-DEngineID=<s>
-DGuiID=<s>
-Did<id> : Specify the Designer session's unique id
-Dit<it> : Specify the Designer session's execution iteration number
-Dt<timestamp> : Specify the Designer session's execution timestamp
-Dscan : Execute in Data Scan mode
-Dclean : Cleanup any Data Scan temporary files
-DDataScanRows =<n>
-T<TraceNumber> : Trace numbers. The numbers are:
-1 : Trace all
1 : Trace row
2 : Trace plan
4 : Trace session
8 : Trace dataflow
16 : Trace transform
32 : Trace user transform
64 : Trace user function
128 : Trace ABAP Query
256 : Trace SQL For SQL transforms
512 : Trace SQL For SQL functions
1024 : Trace SQL For SQL readers
2048 : Trace SQL For SQL loaders
4096 : Trace Show Optimized DataFlows
8192 : Trace Repository SQL
524288 : Trace Nested View Processing
1048576 : Trace Assemblers
4194304 : Trace SAP RFC(BAPI) Function Call
33554432 : Trace adapter/client calls
67108864 : Trace broker communication layer
2147483648 : Trace Audit data
-l<FileName> : Name of the trace log file
-z<FileName> : Name of the error log file (only if any error occurs)
-c<FileName> : Name of the config file
-w<FileName> : Name of the monitor file (must be used together with option -r)
-r : Monitor sample rate (# of rows)
-test : Execute real-time jobs in batch test mode
-nt : Execute in single threaded mode
-np : Execute in single process mode
-no_audit : Execute with Audit turned off
-no_dq_capture : Execute with Data quality statistics capture turned off
-Ksp<SystemConfiguration> : Execute with system configuration
-Ck : Execute in checkpoint mode
-Cr : Execute in checkpoint recovery mode
-Cm<MachineName> : Name of machine that administrates this job
-Ca<AccessServerName> : Name of access server that administrates this job
-Ct<JobType> : Type of this job (e.g. -CtBatch or -CtRTDF)
-Cj<JobServerHostName> : Name of job server's host that executes this job
-Cp<Port> : Port of job server that executes this job
-CSV : Commandline Substitution Parameters (e.g. -CSV"$$DIR_PATH=C:/temp")
-U<User> : Repository login user
-P<Password> : Repository login password
-S<Server> : Repository server name
-N<DatabaseType> : Repository database type
-Q<Database> : Repository database
-g : Repository using Windows Authentication (Microsoft SQL Server only)
-X : Export the repository to file "repo_export.atl"
-XX[L] : Export the repository to file "export.xml"
-XI<Filename.xml> : Import information into the repository
-Xp@<ObjectType>@<FileName> : Exports all repository objects of the specified type to the specified file in ATL format.
-Xp@<ObjectType>@<FileName>@<ObjectName> : Export the specific repository object to the ATL file
-Xp@<ObjectType>@<FileName>@<ObjectName>@DE: Export the specific repository object and its dependents with datastore information to the ATL file.
-Xp@<ObjectType>@<FileName>@<ObjectName>@D : Exports the specified repository object and its dependents to the specified file in ATL format, excluding datastore information.
-XX[L]@<ObjectType>@<FileName> : Export the specific repository objects to the XML file
-XX[L]@<ObjectType>@<FileName>@<ObjectName> : Export the specific repository object to the XML file
-XX[L]@<ObjectType>@<FileName>@<ObjectName>@DE: Export the specific repository object and its dependents with datastore information to the XML file
-XX[L]@<ObjectType>@<FileName>@<ObjectName>@D : Export the specific repository object and its dependents without datastore information to the xml file
<ObjectType> can be one of the following
P : Exports all Projects
J : Exports all Jobs
W : Exports all Workflows
D : Exports all Dataflows
T : Exports all Idocs
F : Exports all user defined File formats
X : Exports all XML and DTD Message formats
S : Exports all Datastores
C : Exports all Custom functions
B : Exports all COBOL Copybooks
E : Exports all Excel workbooks
p : Exports all System Profiles
v : Exports all Substitution Parameter Configurations
K : Exports all SDK transform Configurations
[L] - Optionally, export a lean XML.
-XC : Compact repository
-XV<ObjectType>@<ObjectName> : Validate object of type <ObjectType> that exists in the repository
<ObjectType> can be one of the following when validating objects
J : Job
W : Workflow
D : Dataflow
T : ABAP Transform
F : File format
X : XML Schema or DTD Message format
S : Datastore
C : Custom function
B : COBOL Copybook
E : Excel workbook
p : System Profile
v : Substitution Parameter Configuration
K: SDK Transform Configuration
-XR<ObjectType>@<ObjectName> : Remove object of type <ObjectType> from the repository where ObjectName can be "datastore"."owner"."name" in case of objects (for example, table, stored procedure, domain, hierarchy, or IDOC) contained in a datastore.
<ObjectType> can be any of the object types mentioned for XV option. In addition they can be one of the following
P : Project
t : Table or Template Table
f : Stored procedure or function
h : Hierarchy
d : Domain
i : IDOC
a : BW Master Transfer Structure
b : BW Master Text Transfer Structure
c : BW Master Transaction Transfer Structure
e : BW Hiearchy Transfer
x : SAP Extractor
-Xi<ObjectType>@<ObjectName> : Imports the specified object into the repository.
<ObjectType> is the same as -XR above
-x : Export internal built-in function information
-xi<datastore> : Print datastore's imported objects to file "<datastore>_imported_objects.txt"
-f<Filename.atl>[@NoUpgrade] : Import information from ATL into the repository. By default this option upgrades the SDK Tranforms prior to importing them to repository, and does not import the read-only configurations. Specify @NoUpgrade to ignore the upgrade step or to import read-only configuration ATLs (e.g. sample_sdk_transform.atl).
-F<Datastore.Owner.Function> : Import function(s)
-H<filename> : Import a DTD or XML file to Repo
-I<Datastore.Owner.Table> : Import a single table
-M<Datastore> : Import tables and functions
-Y<Datastore.Owner.Treename> : Import a tree class
-el<Datastore.Owner.DBLink> : Import a database link.
-et<Datastore> : Print all imported database links for the current Datastore.
-G<guid> : Execute a session specified by a GUID
-s<Session> : Execute a session
-p<Plan> : Execute a plan
-passphrase<Passphrase> : Import/export the passwords from/to atl using the passphrase.
-epassphrase<base64-encoded-passphrase> : Same as -passphrase except that it accepts base64 encoded data to allow any special character in the passphrase. The passphrase must have been transcoded to UTF8 character set prior to applying base64 encoding.
-GV<global var assign list> : A list of global variable assignments, separated by semicolons t the whole list in double-quotes.
-a<ABAPProgram> : Generate ABAP code
-V<name=value> : Set the environment variable <name> with <value>
-L<list of value> : List of Object Labels from UI (separated by , or ; or space) to filter Use double quotes around list if space used as a separator.
-yr"<repository parameter file in quotes>" : Read repository information from "file" (default path: %link_dir%/conf/)
-gr"<repository parameter file in quotes>" : Write repository information to "file" (default path: %link_dir%/conf/)
-jd"<datastore delta file in quotes>" : Modify datastore values using "file" (default path: %link_dir%/conf/)
-test_repo : Test repository connection
-b : Populate AL_USAGE table
-ep : Populate AL_PARENT_CHILD table
-ec : Populate AL_COLMAP and AL_COLMAP_TEXT tables
Tree following options are for portable database targets (controlled release).
-WE : Delete properties of portable targets for datastore's database types other than default.
-WP : Populate properties of all portable targets for all datastore's database types.
-WD<datastore> : Datastore to which -WE and/or -WP is applied. If <datastore> was not specified, the option will apply to all portable targets.
-ClusterLevel<Distribution level> : Execute job with distribution level (e.g. -ClusterLevelJOB, -ClusterLevelDATAFLOW, -ClusterLevelTRANSFORM for sub data flow)
Configurations at BW system:
1) Log on to the SAP BW system.
2) Enter T code ‘SALE’ to create new logical system:

3) To create a logical system, choose Define Logical System.
4) Go to Transaction RSA1 to create RFC connection.
5) Select Source Systems in the Modeling navigation pane on the left.
6) Navigate to BO DataServices right click and select create.

7) Enter Logical System Name and Source System Name as shown above and hit Continue.

8) Data Services will start an RFC Server program and indicates to SAP BI that it is ready to receive RFC calls. To identify itself as the RFC Server representing this SAP BI Source System a keyword is exchanged, in the screen shot above it is "BODREP". This is the Registered Server Program, the Data Services RFC Server will register itself with at SAP. Therefore, provide the same Program ID that you want to use for the call of the RFC Server on Data Services side. All other settings for the Source System can remain on the default settings.
To complete the definition of the Source System, save it.

NOTE: We have to use the same Program ID while creating RFC connection in Management Console(BODS).

2 Expand to the new "SAP Connections" node and open the "RFC Server Interface" item. In the Configuration tab a new RFC Server is added so that it can register itself inside the SAP System with the given PROGRAM_ID.

3 Start the RFC server from tab ‘RFC server interface status” :

4 Go to BW and check the connection :

It will show message like below:


2 Right click on header and create new application component(Here it’s ZZ_EMPDS) :


3 Right click on application component and create a new datasource:

4 Fill the information for datasource as shown below :
General Info. Tab

Extraction Tab

Fields Tab: Here we’ll define the structure of the BW target and save it.

5 Now, BW will automatically create a new InfoPackage as shown below :

1 Right click and create a new data store for BW target and fill the required BW system detail as shown below :

2 Right click on transfer structure and import the datasource( here its transaction datasource ‘ZBODSTGT’ :


3 Right click on File format and create a new file format as shown below :

4 Create a BODS job where Source is flat file and target is BW data source(Transfer structure) as shown below :

Where query mappings are as shown below:

BODS job to load data in BW can be executed from both the systems, BODS designer and BW system.
Before Executing the job, We have to do following cofigurations in BW InfoPackage :
Goto BW, Double click on the InfoPackage for respective datasource(ZBODSTGT) and fill the "3rd party selection" details as below and save it.
Repository : BODS repository name
JobServer : BODS running jobserver name
JobName : BODS job name

Job Execution from BW system: Right click and execute infopackage. It will trigger BODS job which will load the data into BW datasource.

OR
Double click on InfoPackag, go to ‘Schedule’ tab and click on start:

Job Execution from BODS designer: Go to BODS designer, Right click on the BODS job and Execute.



When we execute the job, it will generate a request for data extraction from BODS :

2 Select latest request and click on PSA maintenance which will show the data in target datasource.
After loading data to BW datasource, it can be mapped and loaded to any BW target like DSO or Cube using process chain in “Schedule” tab of InfoPackage:
Go to ‘Schedule Option-> Enter Process Chain name in ‘AfterEvent’
OpenText’s ‘Archiving and Document Access (ADA) for SAP’ supports various information management use cases for SAP install-base customers across industries. Organizations are known to use ADA for the following scenarios:
• SAP data archiving: securely store data archive files into OpenText Archive Server and provide combined reporting on both archived and online data using OpenText DocuLink (which is a key Document Access component)
• SAP document archiving: Digitize paper documents, archive and store them into OpenText Archive Server, link archived documents to SAP transaction or master data and provide 360 degree views of SAP data and associated documents using OpenText DocuLink
• SAP Legacy Decommissioning: Archive documents and report outputs (print lists) from legacy SAP systems, link these documents to the target SAP environment and provide search and display capabilities on these documents using DocuLink in the target SAP environment.
The ADA suite provides powerful capabilities for document management & archiving, secure long term storage and search & retrieval functionalities. It also has various integrations into Windows desktop, MS Office applications as well as email clients such as MS Outlook and Lotus Notes using DesktopLink, ExchangeLink and NotesLink components.
Another scenario for which ADA proves useful is in the management of non-SAP documents. By non-SAP documents we mean documents/files which are not related to SAP transactions but are still important for business processes and for retention from a compliance perspective. These could be legal documents, SOP’s, certain types of contracts etc. These documents will be stored into OpenText Archive Server and made available for search and display on SAP screens using OpenText DocuLink. The attributes/metadata values for these documents can be stored into a custom table in SAP. Thus, documents not linked to SAP transactions can also be visible in virtual folders in DocuLink and searched and retrieved by end users. These documents can be “checked-in” to the archive server directly from MS Office applications or emails or the Windows desktop using OpenText DesktopLink, ExchangeLink and NotesLink which are part of the ADA Suite. If such documents are only residing in physical form currently, then they could be digitized and archived using OpenText Enterprise Scan. The solution can also potentially be extended by creating some custom SAP workflows around these documents. For example if a legal document reaches its expiry date a workflow can be triggered to send an email reminder to a designated person in the legal team.
Leveraging ADA for non-SAP documents in this manner allows customers to make the most of their investments in SAP and OpenText while ensuring that all documents in the organization are managed and retained using one solution.
Introduction
When calling a function module in SAP using RFC function call, the (BODI-1112394)>. (BODI-1111081) error is a common occurence. This document aims to provide a solution for such cases.
Error Message
For the purposes of demonstration, I've chosen the Function Module GUID_CREATE which is a standard FM in SAP. The requirement is to generate GUIDs in BODS by calling this function module. The so generated GUIDS need to be sotred in a template table. The subsequent use of these stored GUIDS can be used in BODS ETL routines and this varies with the requirements so this documetn will not explore it.
A screenshot of the error message is show below in Fig 1.

The above mentinoed error message occurs because syntactically the function call in the mapping for the GUID column in Fig 1 is incorrect for BODS validation.The validation failure occurs because the BODS Validation treats the RFC_FUNCTION mapping as incorrect without any input parameters being passed in the function call.
The Function Module
The Import and Export parameters definition for the FM GUID_CREATE is shown in Fig 2 below. the FM can be viewed in transaction SE37.

From Fig 2 it is clear that the Function Module does not need an input parameter and hence just invoking the FM will provide the GUID output as defined in the Export parameters of the FM. when this Function module is executed in SAP, it works without any errors and returns the GUID as expected (Fig 3).

However in BODS, the syntax error occurs because there are no import parameters for this function module.
How to Resolve this situation ?
In order to resolve this error, there should be an input parameter defined for the RFC_FUNCTION call in order to complete the syntax for BODS Validation to be successful. This can be achieved by creating a custom Function Module (ZGUID_CREATE) in SAP that calls the original FM GUID_CREATE but also has an import parameter. This import parameter need not be used in the FM but having this import parameter will complete the syntax in BODS for the RFC Function call.
Fig 4 below shows the "Define Input Parameter(s)" section for RFC_FUNCTION call of function module GUID_CREATE.

The definition for the customer Function Module ZGUID_CREATE is shown in Fig 5.

Note that the ZGUID_CREATE function module does not use the declared import parameter in the source code section. The purpose of the import parameter is for the benefit of the RFC_FUNCTION call in BODS. In Fig 6 below the RFC_FUNCTION call contains the input parameter in the "Define Input Parameter(s)".

The RFC_FUNCTION call now is completed syntactically in the mapping for the GUID column as shown below and validates without errors.

This is one way of getting over the eror message with the syntax when calling the function module via RFC function call.
SAP is committed to providing its customers with world-class solutions that help address data quality and information management challenges. In order to make these types of ongoing investments, at times we need to end of life certain technologies as well. As a result, SAP will retire the SAP Rapid Mart products this year. The goal of this communication is to provide a notification to all customers of this end-of-life (“EOL”) action, provide you with details on what products are affected, make available to you various resources for more detailed information, and point you in the right direction for replacement solutions that you can upgrade to.
The following is a list of products that we will discontinue related to SAP Rapid Marts:
Please note that all of these Rapid Mart solutions have also reached the end of their mainstream maintenance. It is important to clearly state that SAP will continue to honor all current maintenance agreements. However, once the current maintenance and support agreements expire, no further support will be available directly from SAP. SAP customers should contact their Account Executive or the Maintenance and Renewals team with questions on the expiration of their current contracts.
Product Upgrade and Future Support Options
DatalyticsTechnologies (”Datalytics”) has announced that it will sell, maintain , support and enhance the Rapid Mart Solutions. Please refer to Datalytics’ press release http://www.news-sap.com/partner-news/) on this important news. Customers may contact Datalytics Technologies directly for more information. SAP makes no representation or warranty with respect to any services or products provided Datalytics.
If you purchase your SAP solution through an SAP reseller or VAR partner, you can also reach out to them for more information on purchasing support from Datalytics.
Resources and Contacts for additional information
If you have any questions about your Rapid Mart products and options moving forward, please contact your SAP Account Executive. If you do not know who your AE is, please contact the customer interaction center (CIC). The CIC is available 24 hours a day, 7 days a week, 365 days a year, and it provides a central point of contact for assistance. Call the CIC at 800 677 7271 or visit them online at https://websmp207.sap-ag.de/bosap-support. Additionally, you can reach out directly to the SAP reseller or VAR partner you have worked with in the past.
This announcement marks the end of life for SAP Rapid Mart solutions. While we are not excited to see these solutions go, we are confident that our customers’ investments in Rapid Mart products remains sound.
Again, we want to emphasize that SAP is highly committed to providing leading enterprise information management solutions that help you to meet your rapidly growing business requirements. We thank you very much for your continued support.
SAP Data Services 4.2 and SAP Information Steward 4.2 entered Ramp-Up back on May 13th 2013 as General Availability for a planned duration of 6 months. As scheduled both have been released to customer on December 6th 2013.
The final products ready for download are:
Note: SAP took the same approach with SAP BI 4.1 released earlier this year whereas they have entered Ramp-Up with SAP BI 4.1 SP00 and was officially released with SAP BI 4.1 SP01.
The software can be downloaded as a full installation or update:
http://service.sap.com/support> Software Downloads > Installations and Upgrades > A - Z Index > D > SAP Data Services > SAP Data Services 4.2
Microsoft Windows:
Linux:
http://service.sap.com/support> Software Downloads > Installations and Upgrades > A - Z Index > I > SAP Information Steward > SAP Information Steward 4.2
Microsoft Windows:
Linux:
Myself and I'm sure many of you have been waiting for this release for quite some time. I'm sure for one or both of the following reasons:
Customers with implementations such as SAP BI 4.0 or IPS 4.0 and SAP DS 4.1 have been left unable to patch BI to SAP BI 4.1 (SP01 or SP02) when it was released few months ago.
This is of course because of the infamous "compatibility matrix". SAP Note 1740516.
Note: I'll be testing this ASAP on my test environment and contact my customers in January for a series of long and awaited BI and DS (IS) updates!!
See my installation notes:
Here are some helpful documentations:
I'll continue to add content here as I learn more. My main focus is BI Platform so this is always going to be architecture related. I'll let much more knowledge able people than me deal with the new features in those products!
See more blogs and articles here: BI Platform, Enterprise Information Management, Data Services and Data Quality, SAP Information Steward.
As always, I'd be happy to hear your comments, suggestions and experiences with these releases.
Thanks!
The goal of this document is to understand and implement the Global Address cleanse Transforms to Assess the quality of the Address data and to figure out the bad address data
Step 1: Create a New Job and add a Dataflow
Step 2: Inside the Dataflow, Select the source of address data from a table as shown below
Step 3: Select the Data Quality Transforms from the local object library pane and select the Global Address cleanse Transform i.e., UK_Address_Cleanse(Based on your address directory & licensing) as shown below
Step 4: Connect the Source data via Query Transform (if needed) and connect with UK_Address_cleanse Transform and then with the Target Table.
Step 5: Now open the Global Address Cleanse Transform and assign the Inbound attributes in the Input Editor as shown below.
Step 6: Goto the Options Tab and select the Address directory path and change the Generate Reportdata option as ‘YES’
Step 7: Go to Output Tab and select the 4 columns(Status Code, Info_Code, Quality_Code, Assignment Level) as shown below
Step 8: Save & Execute the Job. In the Execution properties, select the Export Data Quality Reports option.
Step 9: once the Job is executed, then log in to the Data Services Admin Console and click the Data Quality Reports
Now you can able to see your Job and corresponding Quality Reports got exported.
If you select the Quality Code Summary Report, this will show the Quality of your address data
Each Quality code implies different meaning
And the below Summary chart shows the same.
You can click on each Quality code and drill down up to the record level for making further analysis and corrections.
Cheers
John
Connecting SAP DataServices to Hadoop Hive is not as simple as connecting to a relational database for example. In this post I want to share my experiences on how to connect DataServices (DS) to Hive.
The DS engine cannot connect to Hive directly. Instead you need to configure a Hive adapter from the DS management console which will actually manage the connection to Hive.
In the rest of this post I will assume the following setup:
The DS server will not be installed within the Hadoop cluster, but it will have access to it. Therefore Hadoop need to be installed and configured appropriately on the DS server. I wont’ go to much into detail for this step, because the given environment may be quite different from my tested environment.
Roughly, there are two approaches for installing Hadoop on the DS server:

Ambari – Add host wizard
Before you can start the wizard you need to enable a passwordless login from the Ambari server to the DS server using an SSH private key.
Later in the wizard process, you need to configure the DS server as a client host; this way all required Hadoop libraries, Hadoop client tools and the Ambari agent will be installed and configured on the DS server. Ambari will also monitor the availability of the DS server.
The DS jobserver needs some Hadoop environment settings. These settings mainly specify the Hadoop and Hive home directories on the DS server and some required Hadoop JAR files through CLASSPATH settings. DS provides a script that sources these environments, please check DS Reference Guide 4.2, section 12.1 Prerequisites.
Important: for Hortonworks HDP distributions, DS provides another script than the documented script hadoop_env.sh. For HDP 2.x distributions you should use the script hadoop_HDP2_env.sh instead (this script is only available from DS version 4.2.2 and later).
On the DS server you should be able to start hive and test the connection. For instance by running the HiveQL command show databases:

Test hive connection
Finally, restart the DS jobserver so that it has the same environment settings as your current session. Also make sure that the hadoop_env.sh script will be started during the DS server startup process.
You may check the following documentation to set up the DS Hive adapter:
In my experience these two subjects usually will not work without problem. The tricky part here is to set CLASSPATH correctly for the adapter. This task is not well documented and depends on the Hadoop distribution and version. Therefore you might end in a series of try-and-error configurations:
These steps are described in more detail in the following sections. The Troubleshooting section in the blog Configuring Data Services and Hadoop on SCN may also help.
For the initial setup of the Hive adapter I used the CLASSPATH setting as described in on SCN. For instance, the initial configuration of the Hive adapter looked like this in my test environment:

Initial setup of the Hive adapter
In the DS designer I created a Hive datastore. The first error message I got when saving the datastore was:

Create Hive datastore – error message
The same error message should be visible in the Hive adapter error log:

Hive adapter – error log
The error message means that the Hive adapter tries to use the Java object org.apache.hadoop.hive.jdbc.HiveDriver but cannot find it. You will need to find the corresponding JAR file that contains this Java object and add the full path of this JAR file to the Hive adapter; then return to step 3.1
There will probably be more than one Java object missing in the initial CLASSPATH setting. Therefore you may very well end up in an iterative process of configuring and re-starting the adapter and testing the adapter by saving the datastore in DS designer.
How do I find the JAR file that contains the missing Java object?
In most cases all required Java objects are in JAR files that are already provided by either the DS installation or the Hadoop installation. They are usually located in one of these directories:
I have developed a small shell script that will search for a Java object in all JAR files in a given directory:
[ds@dsserver ~]$ cat find_object_in_jars.sh
#!/bin/sh
jar_dir=$1
object=$2
echo "Object $object found in these jars:"
for jar_file in $jar_dir/*.jar
do
object_found=`jar tf $jar_file | grep $object`
if [ -n "$object_found" ]
then
echo $jar_file
fi
done
exit 0
For example, the script above found the object org.apache.hadoop.hive.jdbc.HiveDriver in the file $HIVE_HOME//lib/hive-jdbc-0.12.0.2.0.10.0-1.jar. The full path of this file need to be added to the CLASSPATH setting of the Hive adapter:

Finding objects in JAR files
Note: the script above is using the jar utility. You need to install a Java development package (such as Java Open SDK) if the jar utility is not available on your DS server.
DS need to connect to a hive server. The hive sever actually splits the HiveQL commands into MapReduce jobs, accesses the data on the cluster and returns the results to the caller. DS 4.2.2 and later versions are using the current hive server called HiveServer2 to connect to Hive. This version of the hive server is the default for most Hadoop clusters.
The older version of hive server, simply called HiveServer, is usually not started per default on current versions of Hadoop clusters. But DS version 4.2.1 only works with the old hive server version.
The old version of hive server can easily be started from the hive client tool, see HiveServer documentation.
The default port number for HiveServer is 10000. But because HiveServer2 might already be running and listening on this port you should define another port for HiveServer, let’s say 10001:

Starting HiveServer
You can start the HiveServer on a node in the Hadoop cluster or on the DS server. I recommend to start it on the same node where HiveServer2 is already running – this is usually a management node within the Hadoop cluster.
It is also worth to test the HiveServer connection from the hive command line tool on the DS server. When calling the hive CLI tool without parameters it does not act as a client tool and does not connect to a hive server (instead it then acts as a kind of rich client). When calling the hive CLI tool with the host and port number parameters it will act as a client tool and connect to the hive server. For instance:

Testing a HiveServer connection
After upgrading either DS or Hadoop you might need to reconfigure the Hive connection.
Upgrading from DS 4.2.1 to 4.2.2 requires a switch from HiveServer to HiveServer2, see section 4 above.
Furthermore, newer releases of DS might use other Java objects. Then the CLASSPATH of the Hive adapter need to be adapted as described in section 3.
After upgrading Hadoop most often the names of jar files have changed because their names contain the version number. For example:

hive*.jar files in $HIVE_HOME/lib
For instance, when upgrading HDP from version 2.0 to 2.1 the HDP upgrade process replaced some jar files with newer versions. The CLASSPATH setting of the Hive adapter need to be modified accordingly. I found this approach quite easy:
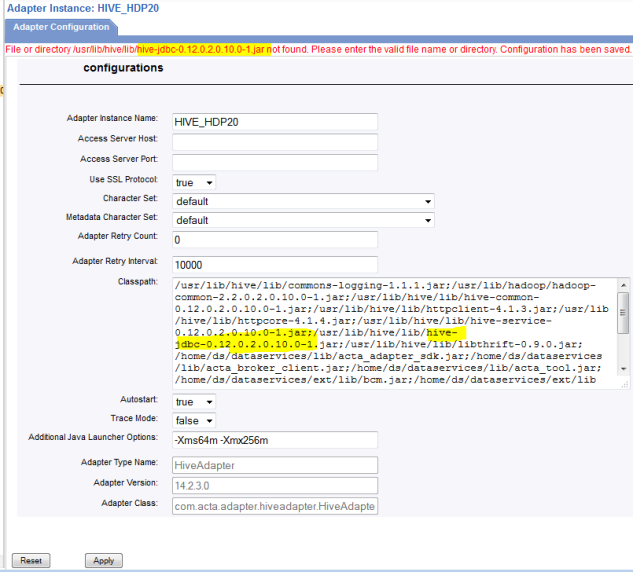
Hive adapter: saving an invalid CLASSPATH
Search for the new file name in the relevant file system directory and modify the CLASSPATH of the Hive adapter accordingly. Save again…
Note: the HDP installation and upgrade process maintains symbolic links without version number in their names. The symbolic links point to the latest version of the jar file. It is of course a good idea to reference these symbolic links in the CLASSPATH setting of the Hive adapter. But unfortunately not all of the required jar files do have symbolic links.
SAP DataServices (DS) supports two ways of accessing data on a Hadoop cluster:
It is difficult to say which approach better to use in DataServices: HDFS files/Pig or Hive? Both, Pig and Hive generate MapReduce jobs in Hadoop and therefore performance should be similar. Nevertheless, some aspects can be considered before deciding which way to go. I have tried to describe these aspects in the table below. They are probably not complete and they overlap, so in many cases they will not identify a clear favorite. But still the table below may give some guidance in the decision process.
| Subject | HDFS / Pig | Hive |
|---|---|---|
Setup connectivity | Simple via HDFS file formats | Not simple. Hive adapter and Hive datastore need to be setup. The CLASSPATH setting for the hive adapter is not trivial to determine. Different setup scenarios for DS 4.1 and 4.2.2 or later releases (see also Connecting SAP DataServices to Hadoop Hive) |
Overall purpose |
| Hive are queries mainly intended for DWH-like queries. They might suit well for DataServices jobs that need to join and aggregate large data in Hadoop and write the results into pre-aggregated tables in a DWH or some other datastores accessible for BI tools. |
Runtime performance |
|
|
Development aspects |
|
|
| Data structure | In general, HDFS file formats will suit better for unstructured or semi-structured data. | There is little benefit from accessing unstructured data via HiveQL, because Hive will first save the results of a HiveQL query into a directory on the local file system of the DS engine. DS will then read the results from that file for further processing. Instead, reading the data directly via a HDFS file might be quicker. |
| Future technologies: Stinger, Impala, Tez etc. | Some data access technologies will improve the performance of HiveQL or Pig Latin significantly (some already do so today). Most of them will support HiveQL whereas some of them will support both, HiveQL and Pig. The decision between Hive and Pig might also depend on the (future) data access engines in the given Hadoop environment. | |
Creating a Data Store by using SQL Server Database
Hi All,
This is a very simple document to create SQL Server Connection in SAP BODS.
Please go through it and provide your comments.
We can create a SQL Server Connection in two ways:
1. Microsoft SQL Server :
Right Click on Data Services as shown below:
Click on New

Select the options and provide the necessary login credentials of SQL Server Database.

Click On Apply and OK to create the connection.
2. ODBC Connection:
Select the Administrative Tools from Control Panel\All Control Panel Items

Click on Add to create new ODBC Connection.
We can use User DSN and System DSN. But System DSN is recommended.
Select SQL Server





Click on OK.
ODBC Connection

We can use this ODBC connection in BODS Data Store SQL Server connection as shown below:

Thank You.
Best Regards,
Arjun
Generally source files are one of the main data source for ETL.
We can load this files as full load and delta load.
This document will give clear understanding for beginners.
Main Points in text file loading:
1) Choosing right delimiter
2) Data Type of the columns
3) Error Handling
4) Delta Loading
Go to Format Tab of the Local Object Library
Select Flat Files
Right Click and Click on New
Fill the options as shown in below screen
I have taken EMP table data in text file for our easy understanding.
Browse the Text files source folder for Root Directory
Select the File Name
Select the delimiter Tab.
We can use custom delimiter also.Here we can see default delimiters comma, semi colon, Tab and space.
I have chosen Tab.

Give the appropriate data types
For First load select the choose the components as shown below components.

Once first load is completed, we can use delta load as shown below:

We can see EMPNO as the Primary Key/Unique record.
So,In table comparison follow the below things:
Table Comparison Tab: Point to EMP table for destination table
Comparison method: Row-by_row select ( Based on your requirement, for more info refer Designer guide)
Input primary key columns : EMPNO
Compare columns : Bring the below columns
ENAME
JOB
MGR
HIREDATE
SAL
COMM
DEPTNO
Use two Map_Operations one for Insert and another for Update the records.
We should use Key_Generation transform to load the Key Generation for newly inserted records.
Thank you.
Best Regards,
Arjun